1 2 3 4 5 6 7 | #!/usr/bin/env python3 import re def count_words(filename): word_counts = {} # Do stuff return word_counts |
This is the final article in the series Basic Data Visualization in Python. In this article, we're going to use everything we learned up to this point to write a program to test the Zipf Hypothesis. If you haven't read the previous article yet, I would suggest reading it.
Right now, we have a big task: test the Zipf Hypothesis on some data. Unless you know the exact code to write for this task, you're going to have to break this task into smaller tasks. To figure out how to break these tasks apart, I ask myself the following questions:
I tend to ask these questions in this order, as knowing where I want to end up helps me make sure I'm going in the right direction and knowing what I have helps me figure out my next step. Once I know where I am and where I'm going, I can then figure out what I need to do to get where I want to be.
At the highest level, we want to test the Zipf Hypothesis, so let's start asking the questions above in the list above.
The Zipf Hypothesis says that the nth most common word in any sufficiently large corpus (body of text or collections of bodies of text) is 1/n times as common as the most common word in the corpus. Therefore, we
We already took care of some of this in a previous article, but we'll go through it again assuming we have nothing.
with open construct we
used back in part 4 of this series.
By separating tasks out and focusing on the inputs and outputs, you make the order of these tasks irrelevant. If you specify the format for the inputs for a task, then any other task with matching outputs can send its outputs to that task.
Since I want to see proof that my program works, I tend to do the tasks that I can use to verify other tasks first. As a practical example, if I wanted to make a game engine, I would set up rendering before I set up physics or sound so that I can make sure the physics and sound work. If I see the player character sliding across the floor when I'm not providing any input, then I know I need to fix my physics.
I won't go through the specific questions for outputs, inputs, and implementation for the rest of the article because our path forward will be obvious enough that we can see what we need to do without going through the full process.
We want to count the words in a file and return some data structure that
contains the words and their counts. Since we want to map the words to their
counts, we'll use a dictionary. We need to know which file we're reading from,
so we'll need to take in either the name of the file or a file handle (the
output of the open function). I have chosen to take in the name of the file
instead of a file handle since I just want to open the file, get the data, and
then close it without doing anything else. I have also chosen not to embed the
filename in this code because this function should do the same thing regardless
of the file it reads. Lastly, since we want to count the words, we'll call the
function count_words. Try to write the code before you see it in the spoiler
below.
1 2 3 4 5 6 7 | #!/usr/bin/env python3 import re def count_words(filename): word_counts = {} # Do stuff return word_counts |
Next, we'll want to open the file, which we can do using the with open
construct.
1 2 3 4 5 6 7 8 | #!/usr/bin/env python3 import re def count_words(filename): word_counts = {} with open(filename, "r") as reader: # Need to add code here return word_counts |
I didn't add a pass statement because I'm going to replace it immediately.
Now that we've created a file handle, we'll want to interact with it. Since we can read a file line by line, we'll do that.
1 2 3 4 5 6 7 8 9 | #!/usr/bin/env python3 import re def count_words(filename): word_counts = {} with open(filename, "r") as reader: for line in reader: # Need to add code here return word_counts |
Now that we have a line of text as a string, we'll want to get rid of anything
that isn't a letter, number, or a space, which we can do using the re module.
We'll need to first get access to the re module before we can use it in our
code, then we'll need to come up with a regular expression that means "anything
that isn't a letter, number, or space", and then we'll need to choose a function
from re that can replace characters.
1 2 3 4 5 6 7 8 9 10 | #!/usr/bin/env python3 import re def count_words(filename): word_counts = {} with open(filename, "r") as reader: for line in reader: clean_line = re.sub(r"[^a-zA-Z0-9\s]", "", line) # More code here return word_counts |
Now that we have a line with just alphanumeric characters and spaces, we'll want some way of getting the individual words, which we can do with just one function.
1 2 3 4 5 6 7 8 9 10 11 | #!/usr/bin/env python3 import re def count_words(filename): word_counts = {} with open(filename, "r") as reader: for line in reader: clean_line = re.sub(r"[^a-zA-Z0-9\s]", "", line) words = clean_line.split() # More code here return word_counts |
Now that we have the individual words, we'll want to loop through them. If we
haven't seen the word before, we'll have to add it to the dictionary. If we have
seen the word before, it will already be in the dictionary and we have to add
1 to its value.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | #!/usr/bin/env python3 import re def count_words(filename): word_counts = {} with open(filename, "r") as reader: for line in reader: clean_line = re.sub(r"[^a-zA-Z0-9\s]", "", line) words = clean_line.split() for word in words: if word in word_counts: word_counts[word] += 1 else: word_counts[word] = 1 return word_counts |
And we're done with this function.
default_dict and CounterWe could get rid of the if else check in count_words if we had instead used
a default_dict and we could have used a Counter
object to do what this function does, but I wanted you to get more practice with
the fundamentals before you used the fancy stuff.
We wrote a function that gets us a dictionary with word counts and we don't have any syntax errors, but the computer understanding what we've written and being able to execute it doesn't mean that we don't have any errors. In fact, I've intentionally left a logic error in the code that you won't be able to pick up unless you've done some text processing before, you want to analyze the code for way too long, or you look at the output and see if you can find anything weird. In almost every case, looking at the output will save you the most time most consistently.
To check our work, we'll want to format the output (sort words by their counts) and then look at it with human eyes. Then, we'll write it to a file that we can scroll through at our leasure. We're going to want to write a few things:
main function to connect everything.
I'm going to start with the main function and add things to it as they come
up. I'm going to create the main function, call it at the end of the file, and
add some code to call count_words.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | #!/usr/bin/env python3 import re def count_words(filename): word_counts = {} with open(filename, "r") as reader: for line in reader: clean_line = re.sub(r"[^a-zA-Z0-9\s]", "", line) words = clean_line.split() for word in words: if word in word_counts: word_counts[word] += 1 else: word_counts[word] = 1 return word_counts def main(): word_counts = count_words("sample-text.txt") main() |
We then need to sort them in descending order by their counts. We no longer need
the dictionary structure and we'll want to get the items using
word_counts.items().
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | #!/usr/bin/env python3 import re def count_words(filename): word_counts = {} with open(filename, "r") as reader: for line in reader: clean_line = re.sub(r"[^a-zA-Z0-9\s]", "", line) words = clean_line.split() for word in words: if word in word_counts: word_counts[word] += 1 else: word_counts[word] = 1 return word_counts def main(): word_counts = count_words("sample-text.txt") sorted_word_counts = sorted(word_counts.items(), key = lambda x: -x[1]) main() |
I could have also set reversed = True in the parameters, but since I was
already using a lambda function, I decided to just make it negative so it's
sorted in reverse order.
Now, we just need to loop through the sorted_word_counts and write them to a
file. Since main should focus on connecting different things together, I'm
going to make another function called save_word_counts_to_file that takes in
the sorted list of words and the output file, loops through them, and prints
them out to to a file.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | #!/usr/bin/env python3 import re def save_word_counts_to_file(word_counts, word_count_file): with open(word_count_file, "w") as writer: for word in word_counts: writer.write(word[0] + " " + str(word[1]) + "\n") def count_words(filename): word_counts = {} with open(filename, "r") as reader: for line in reader: clean_line = re.sub(r"[^a-zA-Z0-9\s]", "", line) words = clean_line.split() for word in words: if word in word_counts: word_counts[word] += 1 else: word_counts[word] = 1 return word_counts def main(): word_counts = count_words("sample-text.txt") sorted_word_counts = sorted(word_counts.items(), key = lambda x: -x[1]) save_word_counts_to_file(sorted_word_counts, "word-counts.txt") main() |
If we look through sample-text.txt, we'll find that The and the are
counted as different words because one has capital letters and one doesn't. We
can handle this problem by just making every word lowercase.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | #!/usr/bin/env python3 import re def save_word_counts_to_file(word_counts, word_count_file): with open(word_count_file, "w") as writer: for word in word_counts: writer.write(word[0] + " " + str(word[1]) + "\n") def count_words(filename): word_counts = {} with open(filename, "r") as reader: for line in reader: clean_line = re.sub(r"[^a-zA-Z0-9\s]", "", line).lower() words = clean_line.split() for word in words: if word in word_counts: word_counts[word] += 1 else: word_counts[word] = 1 return word_counts def main(): word_counts = count_words("sample-text.txt") sorted_word_counts = sorted(word_counts.items(), key = lambda x: -x[1]) save_word_counts_to_file(sorted_word_counts, "word-counts.txt") main() |
If the is not the most common word in word-counts.txt, then you've made an
error somewhere (though copying and pasting the code will get you a right
answer).
We're going to use a continuous version of the Zipf Distribution known as the Pareto distribution. We'll also not normalize it because we don't need to. Anyway, I'll just give you most of the code for this section since I'm focusing on the code and less on the math and you won't be able to figure out what to do on your own from what I've taught you in this series, so you would have to look up the right functions. We're going to
pareto function,
x values, which refer to the rank in the frequency table (the
most common word gets 1, the second most common word gets 2, etc.)
scipy.optimize.curve_fit to fit the function to the data,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | #!/usr/bin/env python3 import re from scipy.optimize import curve_fit as fit def save_word_counts_to_file(word_counts, word_count_file): with open(word_count_file, "w") as writer: for word in word_counts: writer.write(word[0] + " " + str(word[1]) + "\n") def pareto(x, x_m, alpha): return (x_m / x) ** alpha def pareto_fit(counts): word_ranks = list(range(1, len(counts) + 1)) popt, pcov = fit(pareto, word_ranks, counts, p0=[counts[0], 1]) perc_std_dev = lambda var, val: str(100 * var ** 0.5 / val) + "%" print("x_m:\t" + str(popt[0]) + u" \u00B1 " + perc_std_dev(pcov[0][0], popt[0])) print("alpha:\t" + str(popt[1]) + u" \u00B1 " + perc_std_dev(pcov[1][1], popt[1])) return popt def count_words(filename): word_counts = {} with open(filename, "r") as reader: for line in reader: clean_line = re.sub(r"[^a-zA-Z0-9\s]", "", line).lower() words = clean_line.split() for word in words: if word in word_counts: word_counts[word] += 1 else: word_counts[word] = 1 return word_counts def main(): word_counts = count_words("sample-text.txt") sorted_word_counts = sorted(word_counts.items(), key = lambda x: -x[1]) save_word_counts_to_file(sorted_word_counts, "word-counts.txt") counts = [k[1] for k in sorted_word_counts] popt = pareto_fit(counts) main() |
If we run this code, we'll get the parameters and other stuff printed out. You should get two parameters with a "±_____%" off to the side with a low percentage.
user@comp:~/dev$ ./word_counter.py x_m: 73130.301901723 ± 0.7990259669273722% alpha: 0.8551217323188273 ± 0.077199829346526% user@comp:~/dev$
Now, we're going to bring in matplotlib.pyplot so we can plot the values
and the fit scipy generated for us and see how good the fit is. Like with
scipy and the Pareto stuff, most of this is just calling pyplot functions
for which you can find documentation online.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | #!/usr/bin/env python3 import re from scipy.optimize import curve_fit as fit import matplotlib.pyplot as plt def save_word_counts_to_file(word_counts, word_count_file): with open(word_count_file, "w") as writer: for word in word_counts: writer.write(word[0] + " " + str(word[1]) + "\n") def pareto(x, x_m, alpha): return (x_m / x) ** alpha def pareto_fit(counts): word_ranks = list(range(1, len(counts) + 1)) popt, pcov = fit(pareto, word_ranks, counts, p0=[counts[0], 1]) perc_std_dev = lambda var, val: str(100 * var ** 0.5 / val) + "%" print("x_m:\t" + str(popt[0]) + u" \u00B1 " + perc_std_dev(pcov[0][0], popt[0])) print("alpha:\t" + str(popt[1]) + u" \u00B1 " + perc_std_dev(pcov[1][1], popt[1])) return popt def count_words(filename): word_counts = {} with open(filename, "r") as reader: for line in reader: clean_line = re.sub(r"[^a-zA-Z0-9\s]", "", line).lower() words = clean_line.split() for word in words: if word in word_counts: word_counts[word] += 1 else: word_counts[word] = 1 return word_counts def gen_plot(popt, counts): word_ranks = list(range(1, len(counts) + 1)) plt.xscale('log') plt.yscale('log') plt.plot(word_ranks, [pareto(k, popt[0], popt[1]) for k in word_ranks], label="Predicted") plt.plot(word_ranks, counts, label="Actual") plt.legend() plt.savefig("word-counts.png") def main(): word_counts = count_words("sample-text.txt") sorted_word_counts = sorted(word_counts.items(), key = lambda x: -x[1]) save_word_counts_to_file(sorted_word_counts, "word-counts.txt") counts = [k[1] for k in sorted_word_counts] popt = pareto_fit(counts) gen_plot(popt, counts) main() |
After running this program, you should be able to open word-counts.png and see
that the line has a decent fit with a little bit of a jagged edge at the less
frequent words.
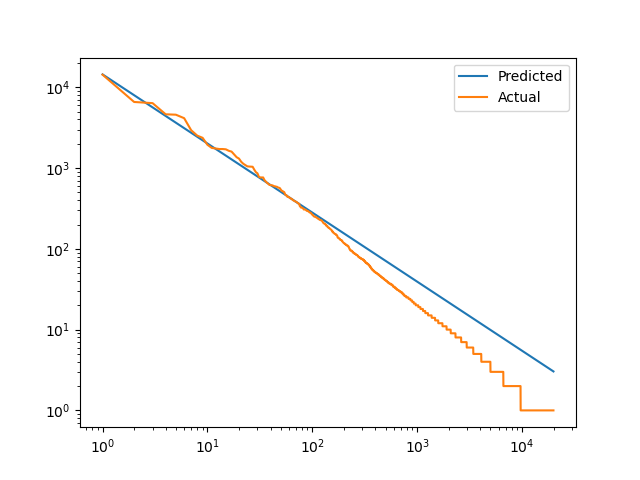
We can clearly see that it's more accurate while for the 100 most common words and less accurate for less common words. Note that since we're doing a log scale on both axes, a large gap on the right means less than a large gap on the left.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | #!/usr/bin/env python3 import re from scipy.optimize import curve_fit as fit import matplotlib.pyplot as plt def save_word_counts_to_file(word_counts, word_count_file): with open(word_count_file, "w") as writer: for word in word_counts: writer.write(word[0] + " " + str(word[1]) + "\n") def pareto(x, x_m, alpha): return (x_m / x) ** alpha def pareto_fit(counts): word_ranks = list(range(1, len(counts) + 1)) popt, pcov = fit(pareto, word_ranks, counts, p0=[counts[0], 1]) perc_std_dev = lambda var, val: str(100 * var ** 0.5 / val) + "%" print("x_m:\t" + str(popt[0]) + u" \u00B1 " + perc_std_dev(pcov[0][0], popt[0])) print("alpha:\t" + str(popt[1]) + u" \u00B1 " + perc_std_dev(pcov[1][1], popt[1])) return popt def count_words(filename): word_counts = {} with open(filename, "r") as reader: for line in reader: clean_line = re.sub(r"[^a-zA-Z0-9\s]", "", line).lower() words = clean_line.split() for word in words: if word in word_counts: word_counts[word] += 1 else: word_counts[word] = 1 return word_counts def gen_plot(popt, counts): word_ranks = list(range(1, len(counts) + 1)) plt.xscale('log') plt.yscale('log') plt.plot(word_ranks, [pareto(k, popt[0], popt[1]) for k in word_ranks], label="Predicted") plt.plot(word_ranks, counts, label="Actual") plt.legend() plt.savefig("word-counts.png") def main(): word_counts = count_words("sample-text.txt") sorted_word_counts = sorted(word_counts.items(), key = lambda x: -x[1]) save_word_counts_to_file(sorted_word_counts, "word-counts.txt") counts = [k[1] for k in sorted_word_counts] popt = pareto_fit(counts) gen_plot(popt, counts) main() |
We've written the entire program and we're done, but we've only dipped our feet
into the depths of python. There are a lot of features and libraries we
haven't covered out there (notably numpy, sympy and its way faster brother
symengine, json, urllib, pygments, etc.) which you can bring into your
project. If you want to do something, chances are that someone's already written
a library you can use. After reading this series, you should be able to search
online "python do some task", find what you need to know, and integrate it into
your programs. You can check out projects like Automate the Boring Stuff with
Python that will go into more detail about specific libraries.
I wrote the static site compiler for this website in python, which is how I
know about pygments (syntax highlighter) and urllib (used to get author
descriptions). sympy is like free Mathematica for python that I've used a
lot, though I had to use symengine for one project because it's much faster
than sympy (symengine is written in C while sympy is written in pure
python). You can use either in a project, but symengine has fewer features.
json makes reading json easy. numpy does math fast.
Go find something you want to do, apply the above process, and get it done.
